近日,科技界迎来了一项令人瞩目的创新成果——微软研究团队推出的开源大型语言模型BitNet b1.58 2B4T。这款模型以独特的低精度架构原生训练而成,拥有20亿参数,却在计算资源需求上实现了大幅缩减。
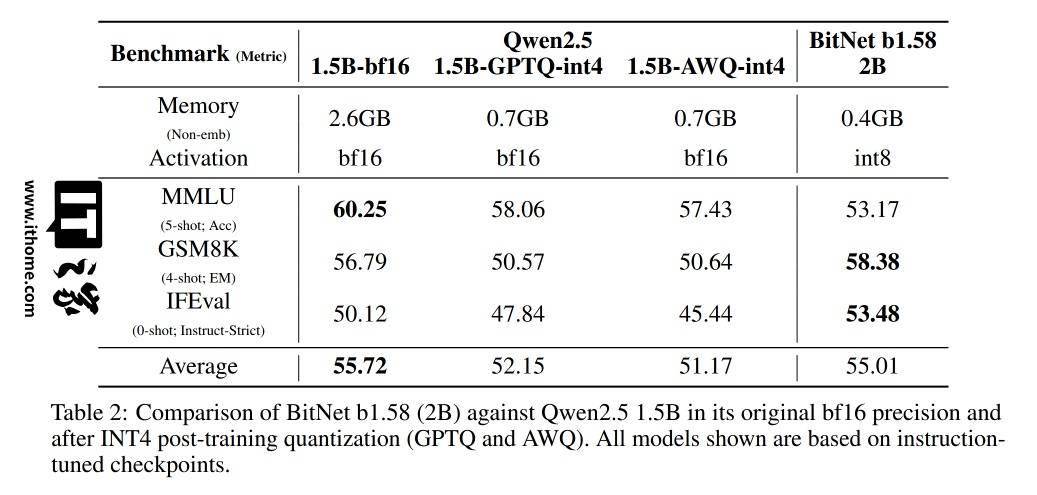
据技术报告显示,BitNet b1.58 2B4T的性能直逼同规模的全精度模型。其非嵌入内存占用仅为0.4GB,这一数据远低于竞品Gemma-3 1B的1.4GB和MiniCPM 2B的4.8GB,展现了其卓越的内存效率。
BitNet的高效秘诀在于其创新的架构。该模型摒弃了传统的16位数值,采用定制的BitLinear层,将权重限制为-1、0、+1三种状态,形成了三值系统。这种设计使得每权重仅需约1.58位信息存储,从而实现了高效的存储和计算。
BitNet在层间激活值上也进行了优化,采用了8位整数量化,形成了W1.58A8的配置。同时,微软还对Transformer架构进行了调整,引入了平方ReLU激活函数、标准旋转位置嵌入(RoPE)以及subln归一化等技术,确保了低位训练的稳定性。这种原生1位训练的方式避免了传统后训练量化(PTQ)可能带来的性能损失。
BitNet b1.58 2B4T的开发历经了三个阶段。首先,基于4万亿token的网络数据、代码和合成数学数据集进行了预训练。随后,通过公开及合成指令数据集进行了监督微调(SFT),如WizardLM Evol-Instruct等。最后,采用直接偏好优化(DPO)方法,利用UltraFeedback等数据集提升了模型的对话能力和安全性。
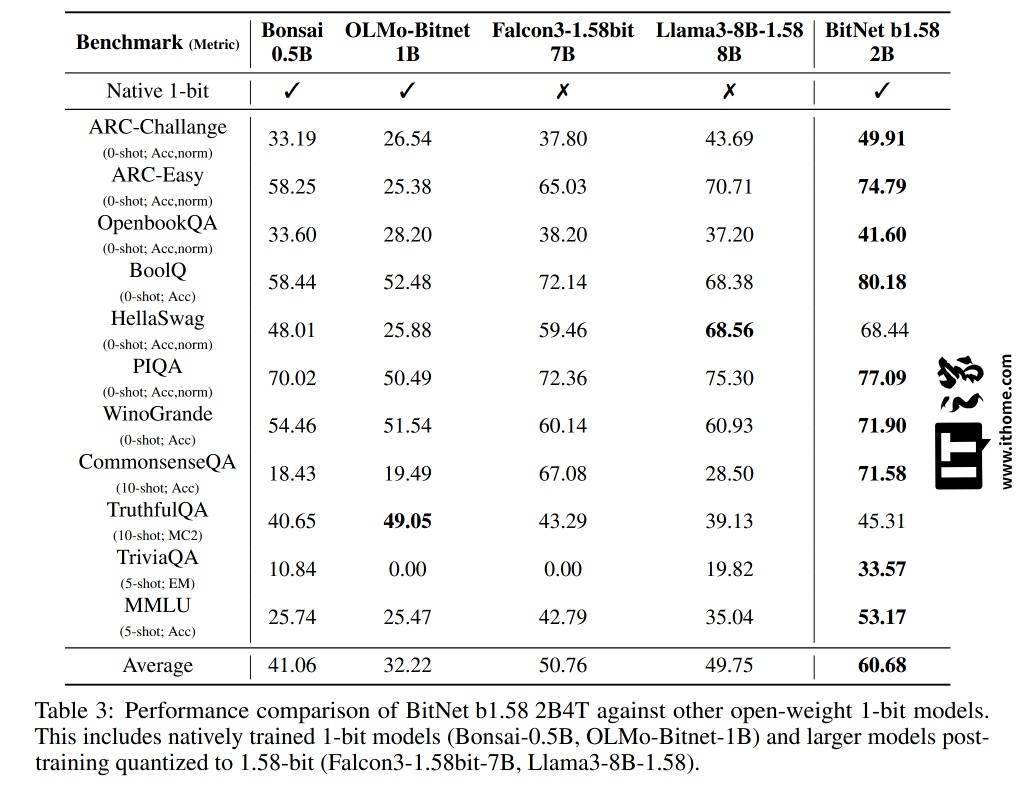
微软的测试结果显示,BitNet在GSM8K(数学)、PIQA(物理常识)等基准测试中表现优异,整体性能与主流1B-2B参数的全精度模型相当。同时,在能耗和CPU解码延迟上也占据了显著优势,每token能耗仅为0.028焦耳,CPU解码延迟为29毫秒。

然而,值得注意的是,BitNet的高效性需要依赖微软提供的专用C++框架bitnet.cpp来实现。如果使用标准工具如Hugging Face transformers库,则无法充分展现其速度和能耗优势。
微软还透露了未来的计划,包括优化GPU和NPU支持,延长上下文窗口至4096 token,并探索更大规模的模型、多语言功能以及硬件协同设计。目前,BitNet b1.58 2B4T已经以MIT许可证在Hugging Face上发布,供社区进行测试和应用。






