阿里通义团队近日宣布,正式推出并开源新一代大语言模型架构Qwen3-Next,标志着大模型技术进入全新发展阶段。这款总参数量达800亿的模型通过创新架构设计,仅需激活30亿参数即可实现与千亿级模型相当的性能,在计算效率与推理速度上取得突破性进展。
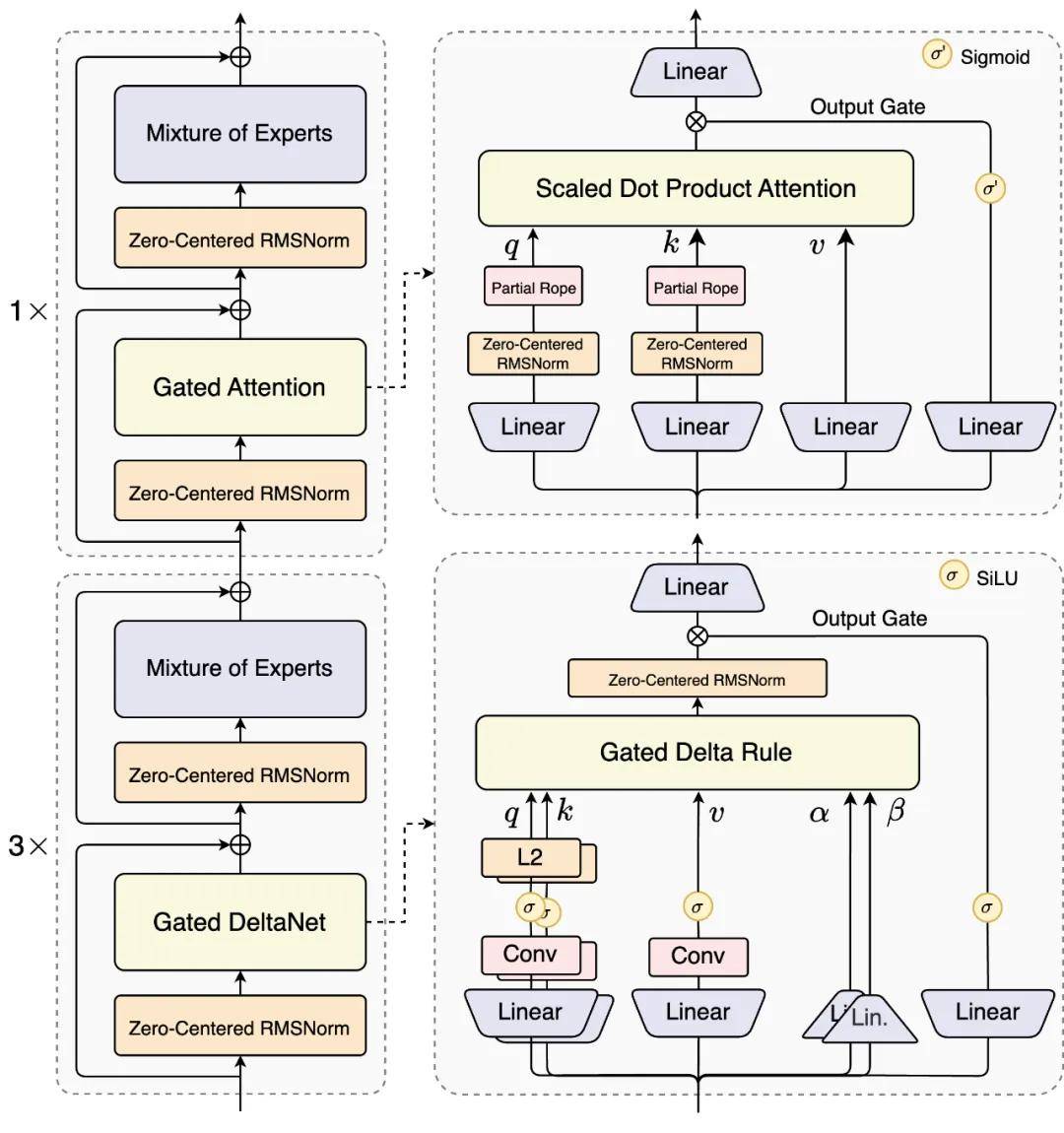
核心技术创新方面,Qwen3-Next采用混合注意力机制与高稀疏度MoE架构的组合方案。通过将75%的神经网络层替换为Gated DeltaNet线性注意力模块,配合25%的标准注意力层,模型在保持长序列处理能力的同时,将计算复杂度从二次方降至线性水平。实验数据显示,这种混合架构在上下文学习任务中显著优于纯线性或标准注意力方案。
在参数效率优化上,研发团队构建了包含512个专家模块的极致稀疏MoE架构。每次推理仅需激活10个路由专家中的3个,配合1个共享专家,实现3.7%的参数激活率。这种设计使800亿参数模型在推理时仅需调动30亿参数,却能达到Qwen3旗舰版2350亿参数模型的性能水平,同时训练成本降低90%以上。
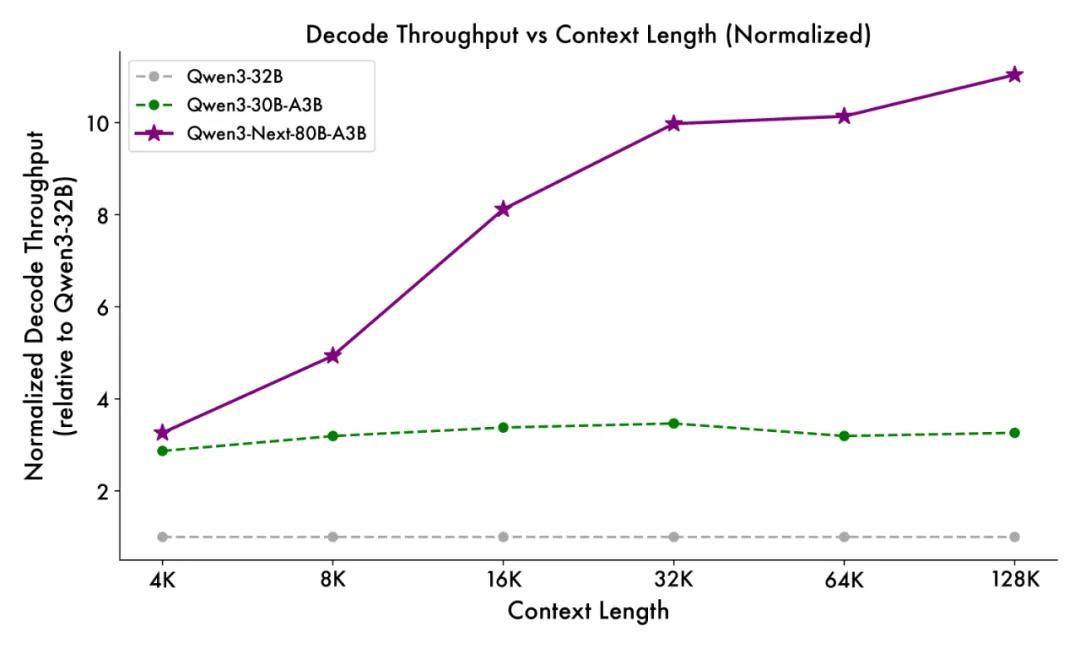
针对长文本处理场景,模型引入多项针对性优化。通过扩展注意力头维度至256、优化旋转位置编码策略,以及采用Zero-Centered RMSNorm归一化方法,有效提升了32K以上超长上下文的推理稳定性。在4K文本长度下,预填充阶段吞吐量较前代模型提升7倍,解码阶段提升4倍;当上下文扩展至32K时,两项指标均实现10倍以上增长。
多token预测(MTP)机制的引入进一步强化了模型效率。该技术通过同步预测多个连续token,使推测解码(Speculative Decoding)的接受率显著提升。在编程能力评测LiveCodeBench v6中,指令调优版本Qwen3-Next-Instruct超越前代旗舰模型;在数学推理基准AIME25测试中,思考增强版本Qwen3-Next-Thinking取得87.8分,全面领先Gemini2.5-Flash-Thinking等同量级模型。
开发团队透露,混合架构的研发历经近一年实验验证。通过系统化对比滑动窗口注意力、Mamba2等方案,最终确定Gated DeltaNet与标准注意力的最优混合比例。在模型初始化阶段,团队采用参数归一化技术确保专家模块均衡激活,配合权重衰减策略有效控制数值稳定性问题。
目前,Qwen3-Next的指令调优版和思考增强版已通过HuggingFace、Kaggle等平台开源,并在Qwen.ai官网提供交互服务。第三方平台anycoder的实时编程测试显示,新模型在代码生成质量与响应速度上均有显著提升。该架构的突破为大规模模型的高效部署提供了全新范式,特别适用于资源受限场景下的高性能AI应用。
